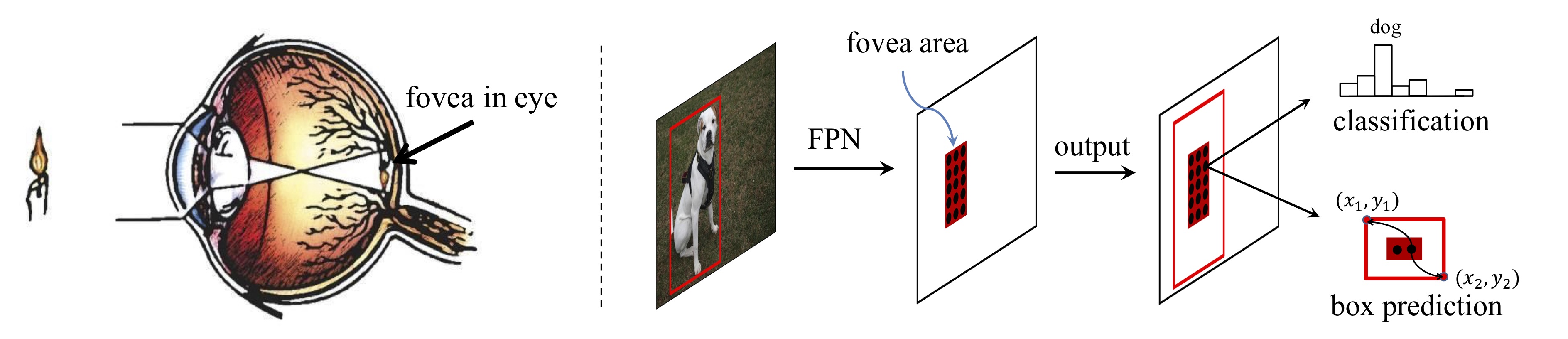
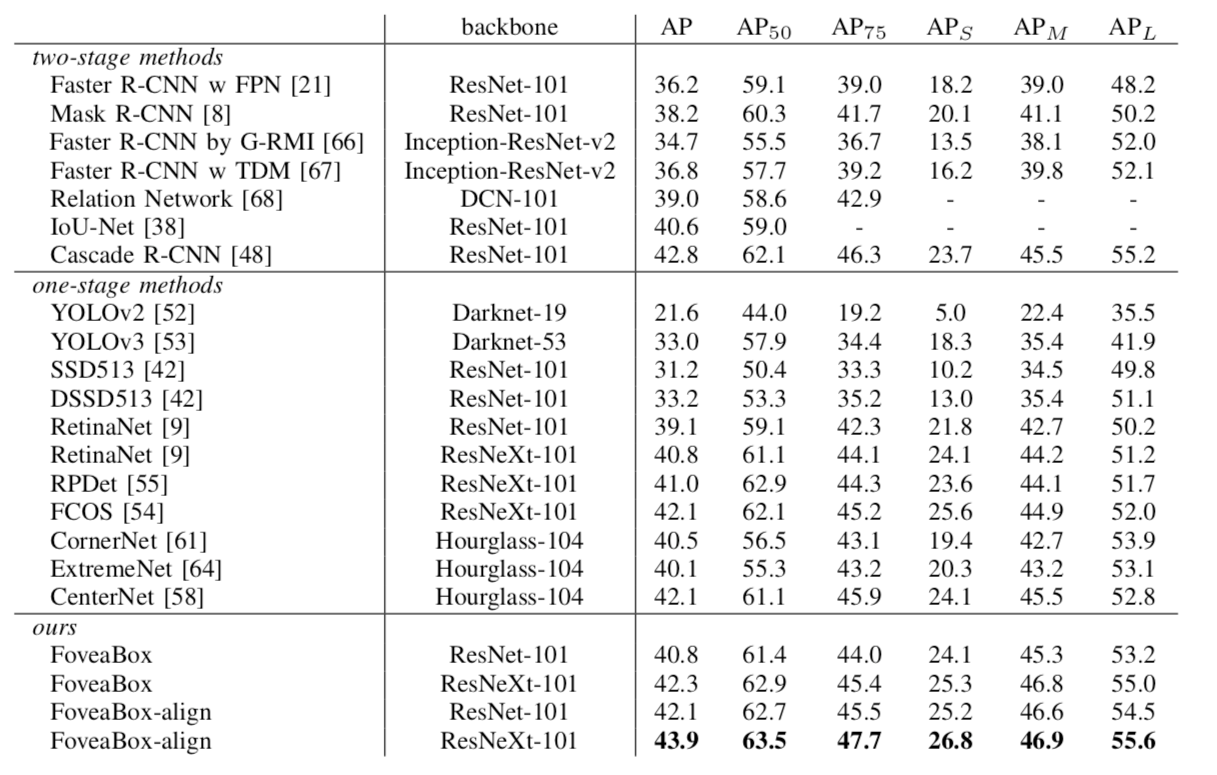
FoveaBox: Beyond Anchor-based Object Detector
1ByteDance AI Lab,
2Tsinghua University,
3University of Pennsylvania
 |
 |
@article{kong2019foveabox,
title={FoveaBox: Beyond Anchor-based Object Detector},
author={Kong, Tao and Sun, Fuchun and Liu, Huaping and Jiang, Yuning and Li, Lei and Shi, Jianbo},
journal={IEEE Transactions on Image Processing},
pages={7389--7398},
year={2020}
}